Spatial autocorrelation
Introduction
Spatial autocorrelation is an important concept in spatial statistics. It is a both a nuisance, as it complicates statistical tests, and a feature, as it allows for spatial interpolation. Its computation and properties are often misunderstood. This chapter discusses what it is, and how statistics describing it can be computed.
Autocorrelation (whether spatial or not) is a measure of similarity (correlation) between nearby observations. To understand spatial autocorrelation, it helps to first consider temporal autocorrelation.
Temporal autocorrelation
If you measure something about the same object over time, for example a persons weight or wealth, it is likely that two observations that are close to each other in time are also similar in measurement. Say that over a couple of years your weight went from 50 to 80 kg. It is unlikely that it was 60 kg one day, 50 kg the next and 80 the day after that. Rather it probably went up gradually, with the occasional tapering off, or even reverse in direction. The same may be true with your bank account, but that may also have a marked monthly trend. To measure the degree of association over time, we can compute the correlation of each observation with the next observation.
Let d be a vector of daily observations.
set.seed(0)
d <- sample(100, 10)
d
## [1] 14 68 39 1 34 87 43 100 82 59
Compute auto-correlation.
a <- d[-length(d)]
b <- d[-1]
plot(a, b, xlab='t', ylab='t-1')
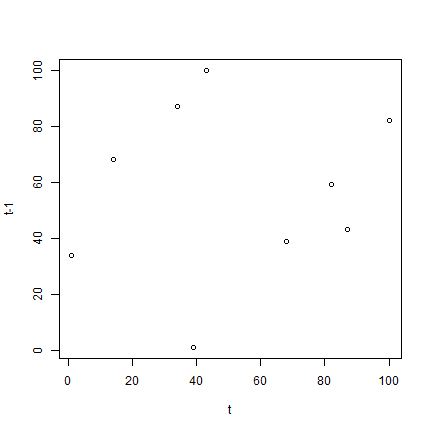
cor(a, b)
## [1] 0.1227634
The autocorrelation computed above is very small. Even though this is a random sample, you (almost) never get a value of zero. We computed the “one-lag” autocorrelation, that is, we compare each value to its immediate neighbour, and not to other nearby values.
After sorting the numbers in d autocorrelation becomes very strong
(unsurprisingly).
d <- sort(d)
d
## [1] 1 14 34 39 43 59 68 82 87 100
a <- d[-length(d)]
b <- d[-1]
plot(a, b, xlab='t', ylab='t-1')
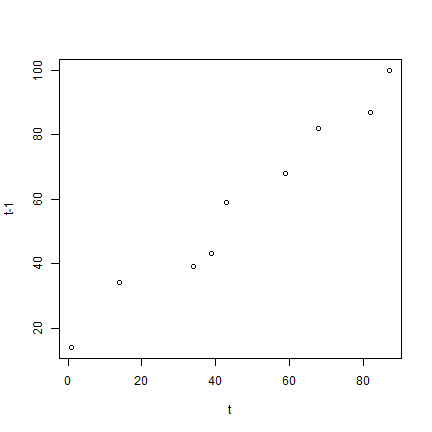
cor(a, b)
## [1] 0.9819258
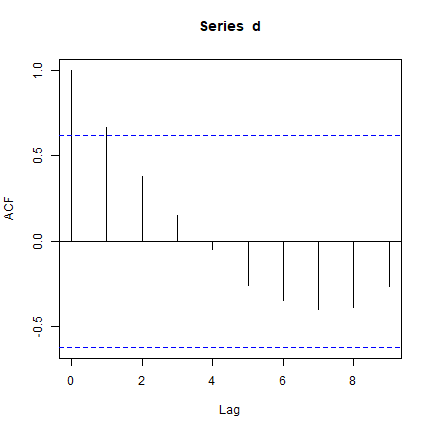
The acf function shows autocorrelation computed in a slightly
different
way
for several lags (it is 1 to each point it self, very high when
comparing with the nearest neighbour, and than tapering off).
acf(d)
Spatial autocorrelation
The concept of spatial autocorrelation is an extension of temporal autocorrelation. It is a bit more complicated though. Time is one-dimensional, and only goes in one direction, ever forward. Spatial objects have (at least) two dimensions and complex shapes, and it may not be obvious how to determine what is “near”.
Measures of spatial autocorrelation describe the degree two which observations (values) at spatial locations (whether they are points, areas, or raster cells), are similar to each other. So we need two things: observations and locations.
Spatial autocorrelation in a variable can be exogenous (it is caused by another spatially autocorrelated variable, e.g. rainfall) or endogenous (it is caused by the process at play, e.g. the spread of a disease).
A commonly used statistic that describes spatial autocorrelation is Moran’s I, and we’ll discuss that here in detail. Other indices include Geary’s C and, for binary data, the join-count index. The semi-variogram also expresses the amount of spatial autocorrelation in a data set (see the chapter on interpolation).
Example data
Read the example data
library(terra)
p <- vect(system.file("ex/lux.shp", package="terra"))
p <- p[p$NAME_1=="Diekirch", ]
p$value <- c(10, 6, 4, 11, 6)
as.data.frame(p)
## ID_1 NAME_1 ID_2 NAME_2 AREA POP value
## 1 1 Diekirch 1 Clervaux 312 18081 10
## 2 1 Diekirch 2 Diekirch 218 32543 6
## 3 1 Diekirch 3 Redange 259 18664 4
## 4 1 Diekirch 4 Vianden 76 5163 11
## 5 1 Diekirch 5 Wiltz 263 16735 6
Let’s say we are interested in spatial autocorrelation in variable “AREA”. If there were spatial autocorrelation, regions of a similar size would be spatially clustered.
Here is a plot of the polygons. I use the coordinates function to
get the centroids of the polygons to place the labels.
par(mai=c(0,0,0,0))
plot(p, col=2:7)
xy <- centroids(p)
points(xy, cex=6, pch=20, col='white')
text(p, 'ID_2', cex=1.5)

Adjacent polygons
Now we need to determine which polygons are “near”, and how to quantify that. Here we’ll use adjacency as criterion. To find adjacent polygons, we can use package ‘spdep’.
w <- adjacent(p, symmetrical=TRUE)
class(w)
## [1] "matrix" "array"
head(w)
## from to
## [1,] 1 2
## [2,] 1 4
## [3,] 1 5
## [4,] 2 3
## [5,] 2 4
## [6,] 2 5
summary(w) tells us something about the neighborhood. The average
number of neighbors (adjacent polygons) is 2.8, 3 polygons have 2
neighbors and 1 has 4 neighbors (which one is that?).
Let’s have a look at w.
w
## from to
## [1,] 1 2
## [2,] 1 4
## [3,] 1 5
## [4,] 2 3
## [5,] 2 4
## [6,] 2 5
## [7,] 3 5
Question 1:Explain the meaning of the values returned by w
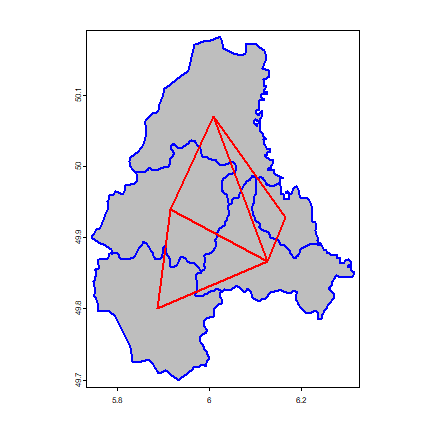
Plot the links between the polygons.
plot(p, col='gray', border='blue', lwd=2)
p1 <- xy[w[,1], ]
p2 <- xy[w[,2], ]
lines(p1, p2, col='red', lwd=2)
We can also make a spatial weights matrix, reflecting the intensity of the geographic relationship between observations (see previous chapter).
wm <- adjacent(p, pairs=FALSE)
wm
## 1 2 3 4 5
## 1 0 1 0 1 1
## 2 1 0 1 1 1
## 3 0 1 0 0 1
## 4 1 1 0 0 0
## 5 1 1 1 0 0
Compute Moran’s I
Now let’s compute Moran’s index of spatial autocorrelation
Yes, that looks impressive. But it is not much more than an expanded version of the formula to compute the correlation coefficient. The main thing that was added is the spatial weights matrix.
The number of observations
n <- length(p)
Get ‘y’ and ‘ybar’ (the mean value of y)
y <- p$value
ybar <- mean(y)
Now we need
That is, (yi-ybar)(yj-ybar) for all pairs. I show two methods to get that.
Method 1:
dy <- y - ybar
g <- expand.grid(dy, dy)
yiyj <- g[,1] * g[,2]
Method 2:
yi <- rep(dy, each=n)
yj <- rep(dy)
yiyj <- yi * yj
Make a matrix of the multiplied pairs
pm <- matrix(yiyj, ncol=n)
And multiply this matrix with the weights to set to zero the value for the pairs that are not adjacent.
pmw <- pm * wm
pmw
## 1 2 3 4 5
## 1 0.00 -3.64 0.00 9.36 -3.64
## 2 -3.64 0.00 4.76 -5.04 1.96
## 3 0.00 4.76 0.00 0.00 4.76
## 4 9.36 -5.04 0.00 0.00 0.00
## 5 -3.64 1.96 4.76 0.00 0.00
We now sum the values, to get this bit of Moran’s I:
spmw <- sum(pmw)
spmw
## [1] 17.04
The next step is to divide this value by the sum of weights. That is easy.
smw <- sum(wm)
sw <- spmw / smw
And compute the inverse variance of y
vr <- n / sum(dy^2)
The final step to compute Moran’s I
MI <- vr * sw
MI
## [1] 0.1728896
This is a simple (but crude) way to estimate the expected value of Moran’s I. That is, the value you would get in the absence of spatial autocorelation (if the data were spatially random). Of course you never really expect that, but that is how we do it in statistics. Note that the expected value approaches zero if n becomes large, but that it is not quite zero for small values of n.
EI <- -1/(n-1)
EI
## [1] -0.25
After doing this ‘by hand’, now let’s use the spdep package to compute Moran’s I and do a significance test. To do this we first need to create a spatial weights matrix
ww <- adjacent(p, "queen", pairs=FALSE)
ww
## 1 2 3 4 5
## 1 0 1 0 1 1
## 2 1 0 1 1 1
## 3 0 1 0 0 1
## 4 1 1 0 0 0
## 5 1 1 1 0 0
Now we can use the autocor function.
ac <- autocor(p$value, ww, "moran")
ac
## [1] 0.1728896
We can test for significance using Monte Carlo simulation. That is the preferred method (in fact, the only good method). The way it works that the values are randomly assigned to the polygons, and the Moran’s I is computed. This is repeated several times to establish a distribution of expected values. The observed value of Moran’s I is then compared with the simulated distribution to see how likely it is that the observed values could be considered a random draw.
m <- sapply(1:99, function(i) {
autocor(sample(p$value), ww, "moran")
})
hist(m)
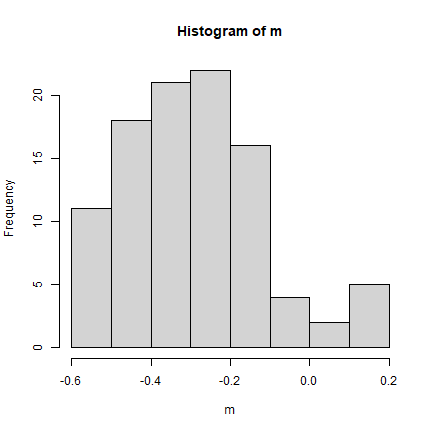
pval <- sum(m >= ac) / 100
pval
## [1] 0.04
Question 2: How do you interpret these results (the significance tests)?
We can make a “Moran scatter plot” to visualize spatial autocorrelation. We first get the neighbouring values for each value.
n <- length(p)
ms <- cbind(id=rep(1:n, each=n), y=rep(y, each=n), value=as.vector(wm * y))
Remove the zeros
ms <- ms[ms[,3] > 0, ]
And compute the average neighbour value
ams <- aggregate(ms[,2:3], list(ms[,1]), FUN=mean)
ams <- ams[,-1]
colnames(ams) <- c('y', 'spatially lagged y')
head(ams)
## y spatially lagged y
## 1 10 7.666667
## 2 6 7.750000
## 3 4 6.000000
## 4 11 8.000000
## 5 6 6.666667
Finally, the plot.
plot(ams, pch=20, col="red", cex=2)
reg <- lm(ams[,2] ~ ams[,1])
abline(reg, lwd=2)
abline(h=mean(ams[,2]), lt=2)
abline(v=ybar, lt=2)
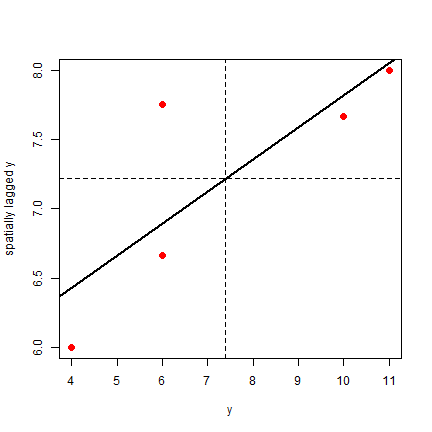
Note that the slope of the regression line:
coefficients(reg)[2]
## ams[, 1]
## 0.2315341
has a similar magnitude as Moran’s I.