High-level methods¶
Several ‘high level’ methods (functions) have been implemented for
RasterLayer objects. ‘High level’ refers to methods that you would
normally find in a GIS program that supports raster data. Here we
briefly discuss some of these. See the help files for more detailed
descriptions.
The high-level methods have some arguments in common. The first argument
is typically ‘x’ or ‘object’ and can be a RasterLayer, or, in most
cases, a RasterStack or RasterBrick. It is followed by one or
more arguments specific to the method (either additional RasterLayer
objects or other arguments), followed by a filename=”” and “…”
arguments.
The default filename is an empty character “”. If you do not specify a
filename, the default action for the method is to return a raster
object that only exists in memory. However, if the method deems that the
raster object to be created would be too large to hold memory it is
written to a temporary file instead.
The “…” argument allows for setting additional arguments that are relevant when writing values to a file: the file format, datatype (e.g. integer or real values), and a to indicate whether existing files should be overwritten.
Modifying a Raster* object¶
There are several methods that deal with modifying the spatial extent of
Raster* objects. The crop method lets you take a geographic
subset of a larger raster object. You can crop a Raster* by
providing an extent object or another spatial object from which an
extent can be extracted (objects from classes deriving from Raster and
from Spatial in the sp package). An easy way to get an extent object is
to plot a RasterLayer and then use drawExtent to visually
determine the new extent (bounding box) to provide to the crop method.
trim crops a RasterLayer by removing the outer rows and columns
that only contain NA values. In contrast, extend adds new rows
and/or columns with NA values. The purpose of this could be to
create a new RasterLayer with the same Extent of another larger
RasterLayer such that the can be used together in other methods.
The merge method lets you merge 2 or more Raster* objects into a
single new object. The input objects must have the same resolution and
origin (such that their cells neatly fit into a single larger raster).
If this is not the case you can first adjust one of the Raster*
objects with use (dis)aggregate or resample.
aggregate and
disaggregate} allow for changing the resolution (cell size) of a ```Raster*`` object. In the case of`aggregate, you need to specify a function determining what to do with the grouped cell values (e.g.mean). It is possible to specify different (dis)aggregation factors in the x and y direction.aggregateanddisaggregate`
are the best methods when adjusting cells size only, with an integer
step (e.g. each side 2 times smaller or larger), but in some cases that
is not possible.
For example, you may need nearly the same cell size, while shifting the
cell centers. In those cases, the resample method can be used. It
can do either nearest neighbor assignments (for categorical data) or
bilinear interpolation (for numerical data). Simple linear shifts of a
Raster object can be accomplished with the shift method or with the
extent method. resample should not be used to create a Raster*
object with much larger resolution. If such adjustments need to be made
then you can first use aggregate.
With the projectRaster method you can transform values of
Raster* object to a new object with a different coordinate reference
system.
Here are some simple examples:
library(raster)
r <- raster()
r[] <- 1:ncell(r)
ra <- aggregate(r, 10)
r1 <- crop(r, extent(-180,0,0,30))
r2 <- crop(r, extent(-10,180,-20,10))
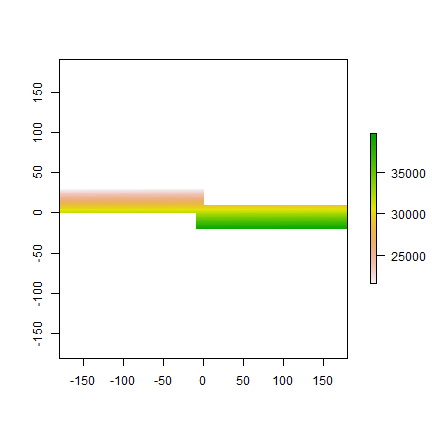
m <- merge(r1, r2, filename='test.grd', overwrite=TRUE)
plot(m)
bf lets you flip the data (reverse order) in horizontal or vertical
direction – typically to correct for a ‘communication problem’ between
different R packages or a misinterpreted file. rotate lets you
rotate longitude/latitude rasters that have longitudes from 0 to 360
degrees (often used by climatologists) to the standard -180 to 180
degrees system. With t you can rotate a Raster* object 90
degrees.
Overlay¶
The overlay method can be used as an alternative to the raster
algebra discussed above. Overlay, like the methods discussed in the
following subsections provide either easy to use short-hand, or more
efficient computation for large (file based) objects.
With overlay you can combine multiple Raster objects (e.g. multiply
them). The related method mask removes all values from one layer
that are NA in another layer, and cover combines two layers by
taking the values of the first layer except where these are NA.
Calc¶
The calc method allows you to do a computation for a single
raster object by providing a function. If you supply a
RasterLayer, another RasterLayer is returned. If you provide a
multi-layer object you get a (single layer) RasterLayer if you use a
summary type function (e.g. sum) but a RasterBrick if multiple
layers are returned. stackApply computes summary type layers for
subsets of a RasterStack or RasterBrick.
Reclassify¶
You can use cut or reclassify to replace ranges of values with
single values, or subs to substitute (replace) single values with
other values.
r <- raster(ncol=3, nrow=2)
values(r) <- 1:ncell(r)
getValues(r)
## [1] 1 2 3 4 5 6
s <- calc(r, fun=function(x){ x[x < 4] <- NA; return(x)} )
as.matrix(s)
## [,1] [,2] [,3]
## [1,] NA NA NA
## [2,] 4 5 6
t <- overlay(r, s, fun=function(x, y){ x / (2 * sqrt(y)) + 5 } )
as.matrix(t)
## [,1] [,2] [,3]
## [1,] NA NA NA
## [2,] 6 6.118034 6.224745
u <- mask(r, t)
as.matrix(u)
## [,1] [,2] [,3]
## [1,] NA NA NA
## [2,] 4 5 6
v <- u==s
as.matrix(v)
## [,1] [,2] [,3]
## [1,] NA NA NA
## [2,] TRUE TRUE TRUE
w <- cover(t, r)
as.matrix(w)
## [,1] [,2] [,3]
## [1,] 1 2.000000 3.000000
## [2,] 6 6.118034 6.224745
x <- reclassify(w, c(0,2,1, 2,5,2, 4,10,3))
as.matrix(x)
## [,1] [,2] [,3]
## [1,] 1 1 2
## [2,] 3 3 3
y <- subs(x, data.frame(id=c(2,3), v=c(40,50)))
as.matrix(y)
## [,1] [,2] [,3]
## [1,] NA NA 40
## [2,] 50 50 50
Focal¶
The focal method currently only works for (single layer) RasterLayer
objects. It uses values in a neighborhood of cells around a focal cell,
and computes a value that is stored in the focal cell of the output
RasterLayer. The neighborhood is a user-defined a matrix of weights and
could approximate any shape by giving some cells zero weight. It is
possible to only compute new values for cells that are NA in the
input RasterLayer.
Distance¶
There are a number of distance related methods. distance computes
the shortest distance to cells that are not NA. pointDistance
computes the shortest distance to any point in a set of points.
gridDistance computes the distance when following grid cells that
can be traversed (e.g. excluding water bodies). direction computes
the direction towards (or from) the nearest cell that is not NA.
adjacency determines which cells are adjacent to other cells, and
pointDistance computes distance between points. See the
gdistance package for more advanced distance calculations (cost
distance, resistance distance)
Spatial configuration¶
The clump method identifies groups of cells that are connected.
boundaries identifies edges, that is, transitions between cell
values. area computes the size of each grid cell (for unprojected
rasters), this may be useful to, e.g. compute the area covered by a
certain class on a longitude/latitude raster.
r <- raster(nrow=45, ncol=90)
r[] <- round(runif(ncell(r))*3)
a <- area(r)
zonal(a, r, 'sum')
## zone sum
## [1,] 0 82236919
## [2,] 1 174010878
## [3,] 2 167714244
## [4,] 3 84469197
Predictions¶
The package has two methods to make model predictions to (potentially
very large) rasters. predict takes a multilayer raster and a fitted
model as arguments. Fitted models can be of various classes, including
glm, gam, randomforest, and brt. method interpolate is similar but
is for models that use coordinates as predictor variables, for example
in kriging and spline interpolation.
Vector to raster conversion¶
The raster packages supports point, line, and polygon to raster
conversion with the rasterize method. For vector type data (points,
lines, polygons), objects of Spatial* classes defined in the sp
package are used; but points can also be represented by a two-column
matrix (x and y).
Point to raster conversion is often done with the purpose to analyze the
point data. For example to count the number of distinct species
(represented by point observations) that occur in each raster cell.
rasterize takes a Raster* object to set the spatial extent and
resolution, and a function to determine how to summarize the points (or
an attribute of each point) by cell.
Polygon to raster conversion is typically done to create a
RasterLayer that can act as a mask, i.e. to set to NA a set of
cells of a raster object, or to summarize values on a raster by
zone. For example a country polygon is transferred to a raster that is
then used to set all the cells outside that country to NA; whereas
polygons representing administrative regions such as states can be
transferred to a raster to summarize raster values by region.
It is also possible to convert the values of a RasterLayer to points
or polygons, using rasterToPoints and rasterToPolygons. Both
methods only return values for cells that are not NA. Unlike
rasterToPolygons, rasterToPoints is reasonably efficient and
allows you to provide a function to subset the output before it is
produced (which can be necessary for very large rasters as the point
object is created in memory).
Summarize¶
When used with a Raster* object as first argument, normal summary
statistics functions such as min, max and mean return a RasterLayer. You
can use cellStats if, instead, you want to obtain a summary for all
cells of a single Raster* object. You can use freq to make a
frequency table, or to count the number of cells with a specified value.
Use zonal to summarize a Raster* object using zones (areas with
the same integer number) defined in a RasterLayer and crosstab
to cross-tabulate two RasterLayer objects.
r <- raster(ncol=36, nrow=18)
r[] <- runif(ncell(r))
cellStats(r, mean)
## [1] 0.5136419
s = r
s[] <- round(runif(ncell(r)) * 5)
zonal(r, s, 'mean')
## zone mean
## [1,] 0 0.5214179
## [2,] 1 0.5436799
## [3,] 2 0.4824496
## [4,] 3 0.4949619
## [5,] 4 0.5191225
## [6,] 5 0.5386785
freq(s)
## value count
## [1,] 0 53
## [2,] 1 134
## [3,] 2 131
## [4,] 3 142
## [5,] 4 123
## [6,] 5 65
freq(s, value=3)
## [1] 142
crosstab(r*3, s)
## layer.2
## layer.1 0 1 2 3 4 5
## 0 9 16 28 25 22 9
## 1 14 42 40 48 32 18
## 2 21 48 43 42 47 27
## 3 9 28 20 27 22 11